Use the SequenceEqual extension method in LINQ.
For example:
var array1 = new byte[] { 1, 2, 3, 4 };
var array2 = new byte[] { 1, 2, 3, 4 };
var areEqual = array1.SequenceEqual(array2); //returns true
Use the SequenceEqual extension method in LINQ.
For example:
var array1 = new byte[] { 1, 2, 3, 4 };
var array2 = new byte[] { 1, 2, 3, 4 };
var areEqual = array1.SequenceEqual(array2); //returns true
I know where I am. My phone knows where it is. Why doesn’t the webpage know where I am?
Think about these scenarios which will become more and more prominent as “the mobile web” starts to prevail:
The key idea that I’m exploring here is the ability for a webpage to access this information through the standard browser interface.
I have a plan for making this a reality.
Windows Mobile has already taken a step towards baking location awareness into the OS with their GPS Intermediate Driver. The idea is that the operating system handles communication with the GPS unit, including all the various protocols. Applications then have a unified API for accessing GPS data. This proxy effect also facilitates non-exclusive access to the GPS.
But this doesn’t go far enough. Even with this unified API, very few applications are actually location aware. More importantly, I don’t want to have to download and install a piece of software on my device just to be able to see movie times. It’s just not going to happen.
We’ve also been making the assumption that location data comes from a GPS. Enter GeoPriv.
With the continuing rollout of VOIP, there are obvious challenges about the loss of location awareness. The current analog network makes call tracing relatively easy. It’s a fixed line of copper and the phone company knows where it terminates. This is a legal requirement for emergency call routing, as well as being immensely useful for scenarios such as a national number auto-routing to your nearest local store. Both of these scenarios become immensely difficult when you can’t even rely on there being a physical phone anymore – a piece of software with a network connection is now a fully fledged communication device that needs to support these scenarios somehow.
There’s an IETF working group tasked to solve this exact problem. The privacy impacts of sharing location data are so important that it’s in the name. They are the “Geographic Location/Privacy working group”, or “GeoPriv“. The best part is, they are living in a reality and delivering useful technology – and fast.
There are a number of key concepts they have identified:
Lets step away from mobile devices briefly and consider the laptop I’m writing this post on. My laptop doesn’t know where it is. Neither does my WiFi router, or my DSL modem. My ISP does though.
At some stage in the future, my modem will start receiving an extra DHCP option. In the same way that my ISP supplies me with network settings like DNS when I connect, they will also start pushing out the address of their Location Information Server. My DSL modem will then push this setting out across my network. Finally, my laptop will be able to query this service to find out my current civic and/or geographic location. The privacy controls around this are beyond the scope of this post.
By asking the service provider for the information, these same techniques also works for mobile devices, 3G data connections, and all those other wonderful wireless technologies. Cell-based triangulation is already in use by phone companies around the world, including our national carrier here in Australia, however the interfaces are in no way standardized. The Location Information Server (LIS) and the HTTP Enabled Location Delivery protocol (HELD) solve this problem.
Now that our device is capitalising on the network ecosystem, getting it into the browser is the easy part. All that’s left is a thin veneer of JavaScript.
Location awareness is only becoming an increasing demand. I want to start the process of rolling in the JS layer now, so that as the supporting technologies come to fruition, we have the access layer to make them useful.
Inline with the XMLHttpRequest object that we’ve all come to know and love, I’ve started writing a spec for a GeographicLocationProvider object.
With XMLHttpRequest, we can write code like this:
var client = new XMLHttpRequest(); client.onreadystatechange = function() { if(this.readyState == 4 && this.status == 200) alert(this.responseXML); } client.open("GET", "http://myurl.com/path"); client.send();I want to be able to write code like this:
var provider = new GeographicLocationProvider(); provider.onreadystatechange = function() { if(this.readyState == 2) alert(this.geographic.latitude); } provider.start();Again, usage is conceptually similar to the XMLHttpRequest object:
- Initialize an instance of the object
- Subscribe to the state change event
- Set it free
The potential states are:
In more complex scenarios, the provider can be primed with a specific request to aid in evaluation of privacy policies and selection of location sources. For example, browsers may choose to hand over state-level civic location data without a privacy prompt. This data could also be obtained from an LIS, without needing to boot up a GPS unit. If the webpage requested highly accurate geographic location data, the browser would generally trigger a privacy prompt and boot up the most accurate location source available.
While we’ve now simplified the developer experience, the complexity of the browser implementation has mushroom clouded. How do we reign this in so that it’s attractive and feasible enough for browser implementers? How do we demonstrate value today?
You might have noticed that in my discussion of the JS layer I drifted away from the GeoPriv set of technologies. While any implementation should be harmonious with the concepts developed by the GeoPriv working group, we aren’t dependent upon their technology to start delivering browser-integrated location awareness today.
There are numerous location sources which can be used:
The civic and geographic schemas have already been delivered by the working group as RFC 4119. There has been an incredible amount of discussion involved in developing a unified schema that can represent civic addresses for anywhere in the world, and this schema should be adopted for consistency. (Do you know the difference between states, regions, provinces, prefectures, counties, parishes, guns, districs, cities, townships, shis, divisions, boroughs, wards, chous and neighbourhoods? They do.)
Who is responsible for delivering this unified location layer?
I keep talking about the browser being responsible for managing all these location sources. Other than the JS layer, all of this infrastructure is client independent, so why don’t we just make the browser a dumb proxy to a unified location service. This service should be a component of the operating system, accessible by software clients (like Skype) and webpages via the browser proxy.
Windows Mobile has already started in the right direction with their GPS Intermediate Driver, however this is only one element of a wider solution.
What do I want?
How am I going to make this happen?
Dunno.
Right now, I’m documenting the start of what will hopefully be a fruitful conversation. Participate in the conversation.
The documentation for System.TimeZoneInfo.GetSystemTimeZones() states:
Returns a sorted collection of all the time zones about which information is available on the local system.
Unfortunately, while the result is technically sorted, it’s a silly sort which shows GMT, then the eastern hemisphere, then the western hemisphere. It seems to be sorted by TimeZoneInfo.DisplayName instead of TimeZoneInfo.BaseUtcOffset.
Luckily this is easily fixed (and concise too thanks to anonymous methods!).
List<TimeZoneInfo> timeZones = new List<TimeZoneInfo>(TimeZoneInfo.GetSystemTimeZones());
timeZones.Sort(delegate(TimeZoneInfo left, TimeZoneInfo right) {
int comparison = left.BaseUtcOffset.CompareTo(right.BaseUtcOffset);
return comparison == 0 ? string.CompareOrdinal(left.DisplayName, right.DisplayName) : comparison;
});
In the devil’s language (VB.NET) you can achieve it using some slightly different code (no anonymous methods in VB.NET):
Dim timeZones As List(Of TimeZoneInfo) = New List(Of TimeZoneInfo)(TimeZoneInfo.GetSystemTimeZones())
timeZones.Sort(New Comparison(Of TimeZoneInfo)(AddressOf CompareTimeZones))
Private Function CompareTimeZones(ByVal left As TimeZoneInfo, ByVal right As TimeZoneInfo) As Integer
Return IIf(comparison = 0, String.CompareOrdinal(left.DisplayName, right.DisplayName), comparison)
End Function
This will result in the list being sorted in the same order that you see under “Adjust Date/Time” in Windows.
Maybe they could fix this in the next release. 🙂 To help make that happen, vote for the issue on Microsoft Connect.
Update – 5 Feb 08: Daniella asked for a VB.NET version, so I’ve updated the post with one. Because VB.NET doesn’t support anonymous methods, you need an extra function somewhere to do the comparison.
Update – 12 Feb 08: Whitney correctly pointed out that the order still wasn’t quite right for time zones that shared the same offset. We need to sort by name as well. I’ve updated the C# and VB.NET version accordingly. I changed Whitney’s version a bit to use the conditional operator so that I could avoid two return statements, as well as translating it to VB.NET. Thanks Whitney!
Update – 15 Feb 08: Added Microsoft Connect link.
I’ve being playing around with an XHTML WYSIWYG editor called XStandard lately. Their actual product is awesome, but before I jumped in and used their supplied ASP.NET wrapper I thought I’d just take a quick look at it in Reflector. Unfortunately, like many redistributed controls, there were some issues that jumped out at me. (This post isn’t a dig at them – they just kicked off the writing idea in my head, although I’d love it if they implemented the relevant changes.)
This post is designed as a quick guide around some of these issues, and represents the generally accepted best practice approach for control development. These were just the first issues that came to mind – in another post I’ll cover rendering best practices, as well as incorporate any suggestions by you.
After a page has finished rendering, it is mostly destroyed in memory. When a postback occurs, the ASP.NET runtime has to rebuild all of the objects in memory. If we use fields as the backing stores for our properties, these values won’t survive the postback and thus your control will be re-rendered differently.
A traditional .NET property might look like this:
private string _spellCheckerURL;
public string SpellCheckerURL
{
get { return _spellCheckerURL; }
set { _spellCheckerURL = value; }
}
But in ASP.NET server controls, we need to write them like this:
public string SpellCheckerUrl
{
get { return (string)ViewState[“SpellCheckerUrl”] ?? string.Empty; }
set { ViewState[“SpellCheckerUrl”] = value; }
}
You might notice my use of the C# coalesce operator (??). Until we store anything in the property, requesting it from view state is going to return null. Using the coalesce operator allows us to specify a default value for our property, which we might normally have specified on the field like so:
private string _spellCheckerURL = string.Empty;
The rule above (store everything in the ViewState) is nice and reliable, but it can also be a bit nasty to the end user – the person who has to suck down your behemoth chunk of encoded ViewState.
For some properties, you can safely lose them then just work them out again. Our rich text editor control gives a perfect example – we don’t need to store the text content in the ViewState because it’s going to be written into our markup and passed back on the post-back. We can (and should) be storing this data in a backing field for the first render, then obtaining it from the request for postbacks.
ASP.NET server controls exist to provide a level of abstraction between the developer, and the actually workings of a control (the markup generated, the postback process, etc). Build your control with that in mind.
The XStandard control is a perfect example of a server control being implemented as more of a thin wrapper than an actual abstraction layer – you need to understand the underlying API to be able to use the control.
Their Mode property looks like this:
public string Mode
{
get { return this.mode; }
set { this.mode = value; }
}
For me as a developer, if the property accepted an enumeration I wouldn’t need to find out the possible values – I could just choose from one of the values shown in the designer or suggested by IntelliSense.
public enum EditorMode
{
Wysiwyg,
SourceView,
Preview,
ScreenReaderPreview
}public EditorMode Mode
{
get { return (EditorMode)(ViewState[“Mode”] ?? EditorMode.Wysiwyg); }
set { ViewState[“Mode”] = value; }
}
This adds some complexity to our control’s rendering – the names of the enumeration items don’t match what we need to render to the page (eg. EditorMode.ScreenReaderPreview needs to be rendered as screen-reader). This is easily rectified by decorating the enumeration, as per my previous post on that topic.
You might also have noticed that the casing of SpellCheckerUrl is different between my two examples above. The .NET naming guidelines indicate that the name should be SpellCheckerUrl, however the XStandard control names the property SpellCheckerURL because that’s what the rendered property needs to be called. The control’s API surface (the properties) should be driven by .NET guidelines, not by rendered output. This comes back to the idea of the control being an abstraction layer – it should be responsible for the “translation”, not the developer using the control.
App-relative URLs in ASP.NET (eg. ~/Services/SpellChecker.asmx) really do make things easy. Particularly working with combinations of master pages and user controls, the relative URLs (eg. ../../Services/SpellChecker.asmx) can be very different throughout your site and absolute URLs (http://mysite.com/Services/SpellChecker.asmx) are never a good idea.
The XStandard control uses a number of web services and other resources that it needs to know the URLs for. Their properties look like this:
[Description(“Absolute URL to a Spell Checker Web Service.”)]
public string SpellCheckerURL
{
get { return this.spellCheckerURL; }
set { this.spellCheckerURL = value; }
}
This made their life as developers easy, but to populate the property I need to write code in my page’s code-behind like this:
editor.SpellCheckerURL = new Uri(Page.Request.Url, Page.ResolveUrl(“~/Services/SpellChecker.asmx”)).AbsoluteUri;
This renders my design-time experience useless, and splits my configuration between the .aspx file and the .aspx.cs file.
All properties that accept URLs should support app-relative URLs. It is the controls responsibility to resolve these during the render process.
Generally, the resolution would be as simple as:
Page.ResolveUrl(SpellCheckerUrl) (returns a relative URL usable from the client page)
however if your client-side code really does needs the absolute URL, you can resolve it like this:
new Uri(Page.Request.Url, Page.ResolveUrl(SpellCheckerUrl)).AbsoluteUri
Because we’re using the powerful URI support built in to .NET, we don’t even need to worry about whether we were supplied an absolute URL, relative URL or file path … the framework just works it out for us.
Either way, it’s your responsibility as the control developer to handle the resolution.
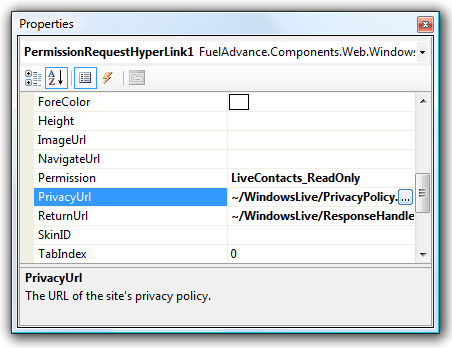
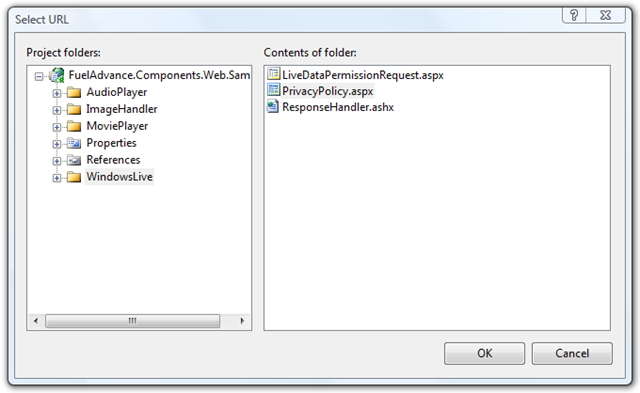
Now that we’ve made it really easy for developers to specify URLs as page-relative, app-relative or absolute, let’s make the designer experience really sweet with this editor (notice the […] button on our property):
That’s as simple as adding two attributes to the property:
[Editor(“System.Web.UI.Design.UrlEditor, System.Design, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a”, typeof(UITypeEditor))]
[UrlProperty]
public string SpellCheckerUrl
{
get { return ViewState[“SpellCheckerUrl”] as string ?? string.Empty; }
set { ViewState[“SpellCheckerUrl”] = value; }
}
IntelliSense reads the XML comments, but the designer reads attributes. Document your control’s API surface using both of them.This is a bit annoying, but really not that hard and well worth it. Make sure to specify the summary in XML, as well as the Category and Description attributes.
Our typical property now looks something like this:
/// <summary>
/// Gets or sets the URL of the return handler (a handler inheriting from <see cref=”PermissionResponseHandler”/>).
/// This should be a URL to a HTTPS resource to avoid a scary warning being shown to the end user.
/// </summary>
[Category(“Behavior”)]
[Description(“The URL of the return handler (a handler inheriting from PermissionRequestReturnHandler).”)]
public string ReturnUrl
{
get { return ViewState[“ReturnUrl”] as string ?? string.Empty; }
set { ViewState[“ReturnUrl”] = value; }
}
If you look closely, you’ll notice the documentation isn’t actually duplicated anyway … the messaging is slightly different between the XML comment and the attribute as they are used in different contexts.
In the spirit of attributes, let’s add some more to really help the designer do what we want.
For properties that aren’t affected by localization, mark them as such to reduce the clutter in resource files:
[Localizable(false)]
Define the best way to serialize the data in the markup. This ensures a nice experience for developers who do most of their setup in the design, but then want to tweak things in the markup directly.
[PersistenceMode(PersistenceMode.Attribute)]
Declare your two-way binding support. If you mark a property as being bindable (which you should) then you also need to implement INotifyPropertyChanged (which you should):
[Bindable(true)]
Declare default values. Doing so means that only properties that are explicitly different will be serialized into the markup, keeping your markup clean.
[DefaultValue(“”)]
Clearly indicate properties that are read-only. Doing so will make the read-only in the designer, rather than throwing an error when the user tries to set them:
[ReadOnly(true)]
If a property isn’t relevant to the design-time experience, hide it.
[Browsable(false)]
[DesignerSerializationVisibility(DesignerSerializationVisibility.Hidden)]
At the class level, it’s also good to define your default property so that it can be auto-selected first in the property grid.
[DefaultProperty(“Text”)]
ASP.NET has a great system for managing client side IDs and avoiding any conflicts – use it.
Use the ClientID property, and where needed, the INamingContainer interface. Don’t create IDs yourself.
Add a ToolboxData attribute to your control class so that users get valid code when they drag it on from the toolbox:
[ToolboxData(“<{0}:XhtmlEditor runat=\”server\”></{0}:XhtmlEditor>”)]
Define a tag prefix so that your controls have a consistent appearance in markup between projects.
[assembly: TagPrefix(“FuelAdvance.Components.Web”, “fa”)]
You only need to do this once per assembly, per namespace. Your AsssemblyInfo.cs file is generally a good place to put it.
Update 6-Nov-07: Clarified some of the writing. Added another screenshot.
This was the question I was faced with last week. I was configuring a VPC image in Sydney, that I was later going to load on to a physical box in San Diego, then use it from anywhere in the world. So which time zone to use?
I decided upon UTC, and now, the more that I think about it, I don’t know why all servers aren’t configured that way.
Advantages to using UTC:
Disadvantages to using UTC:
My recommendation: Run all your servers in UTC (that’s “GMT – Greenwich Mean Time” with “Automatically adjust clock for DST” turned OFF).
Maybe Adam can add this to his standards? 😉